AI pentesting uses AI agents to probe applications the way a skilled human tester would. At its best, it surfaces IDORs, authorization failures, and logic abuse paths: the elusive bugs that automated scanners miss and that show up in real-world breaches. The marketing claims are outpacing the evidence.
Doyensec is an independent application security consultancy. We asked them to run a head-to-head: two real applications, picked at random from a pool of 442, tested at the same price tier with the same credentials, every finding manually validated by two researchers with peer review.
What the numbers actually say
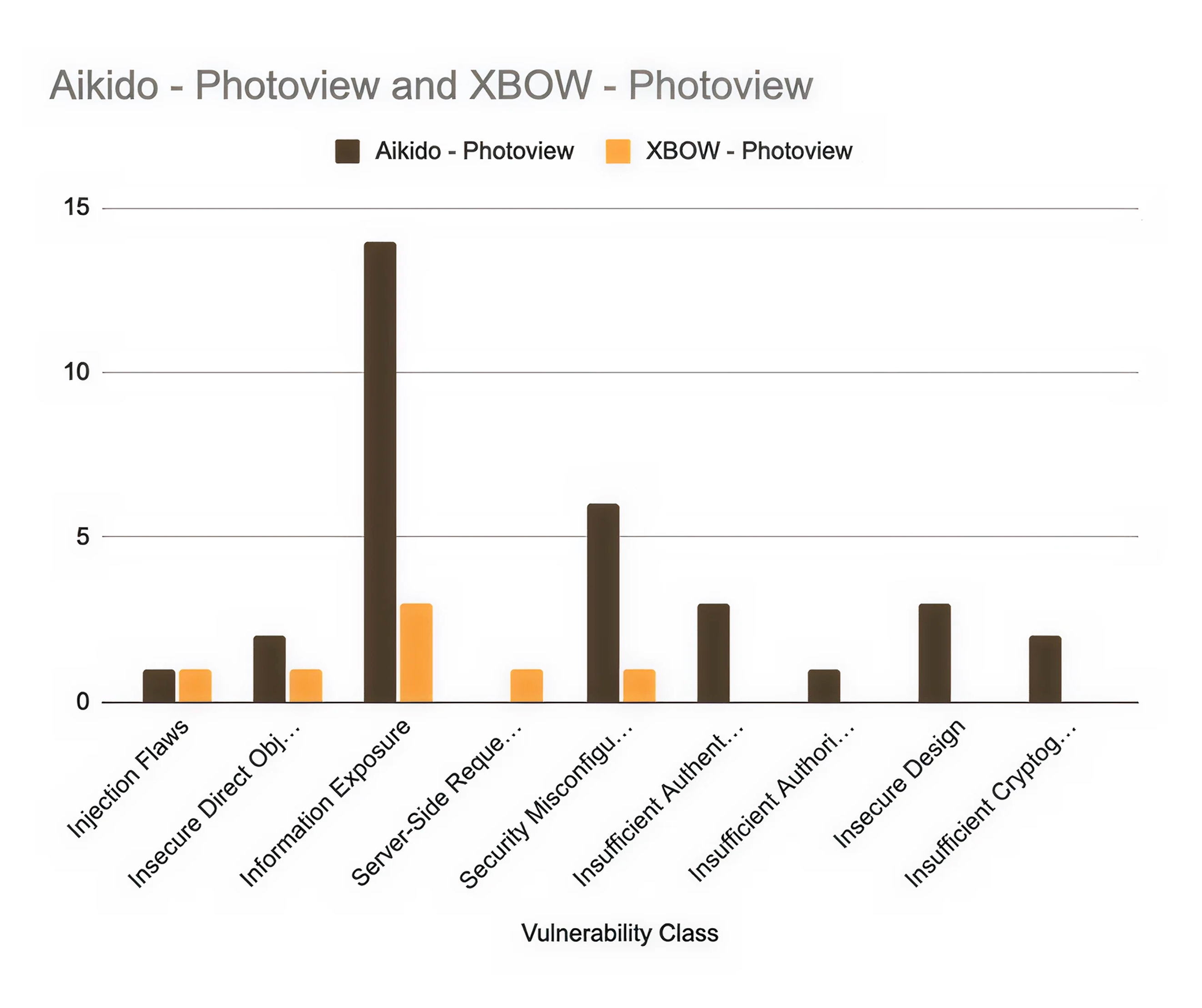
The benchmark tested two applications: Fider, an open-source user feedback platform, and Photoview, a TypeScript/Next.js photo gallery app with role-based access control.
Aikido surfaced 49 verified vulnerabilities. XBOW found 31. That's 58% more at the same price.
Source: Doyensec
The false positive rates are nearly identical. This means the gap isn't about one tool being noisier or less precise. Both tools are roughly calibrated the same way, but Aikido just finds substantially more vulnerabilities.
The overlap stat tells the real story: only 3 matching findings on Fider, 4 on Photoview. Out of 49 and 31 findings respectively, the two tools agreed on fewer than 10% of vulnerabilities. That's not a minor variation. Two tools looking at the same applications found almost entirely different things. The choice of tool has real consequences for what risk you're actually aware of.
Source: Doyensec
Better context produces better results
Aikido ingests the codebase before testing begins. Every test is informed by what the code is supposed to do. For human pentesters, that kind of preparation takes days. For an AI system, it takes seconds. The added cost is effectively zero.
That matters most for the vulnerability classes automated scanners miss. IDORs, authorization failures, and logic abuse paths only become visible when you understand how an application is supposed to work. A tool probing a user endpoint has no way to know that endpoint can be accessed with a different user's ID unless it understands what the authorization logic is supposed to enforce. It can only see what's visible. It can't reason about what should be invisible but isn't.
Doyensec also noted XBOW had one fewer false positive and may have enabled slightly faster finding validation in some cases.
The part buyers don't think about until it's a problem
Coverage is the headline. What happens after you click start matters too.
Getting Aikido configured and running on both applications took under 20 minutes. Self-serve.
XBOW required a sales representative to approve before scanning could begin. Then a DocuSign contract. Once it finally ran, it took 22 support emails, three scan restarts after crashes, a deleted test account, two infrastructure outages that required mid-engagement EC2 upgrades. The Fider report arrived five days after the scan completed, eleven days after the engagement started.
Security teams run pentests under pressure. Eleven days to findings and mid-engagement crashes aren't acceptable.
XBOW includes one retest within 30 days. Aikido offers unlimited retests for 90 days, at no additional cost, with results in minutes. The point of finding a vulnerability is fixing it and confirming the fix. If confirming each fix costs a new engagement, that's either slowing down the remediation cycle or adding budget that wasn't planned for.
Single-user testing isn't enough for role-based applications
XBOW doesn't support multi-user testing or social login. For anyone testing applications with role-based access control, this is a big problem and creates untested paths.
Whole categories of authorization vulnerabilities require testing across multiple user roles. IDORs, privilege escalation, and broken object-level authorization only become visible when you can test what one role can access versus another. If you can only test as one user, those vulnerabilities aren't in scope.
What Doyensec concluded
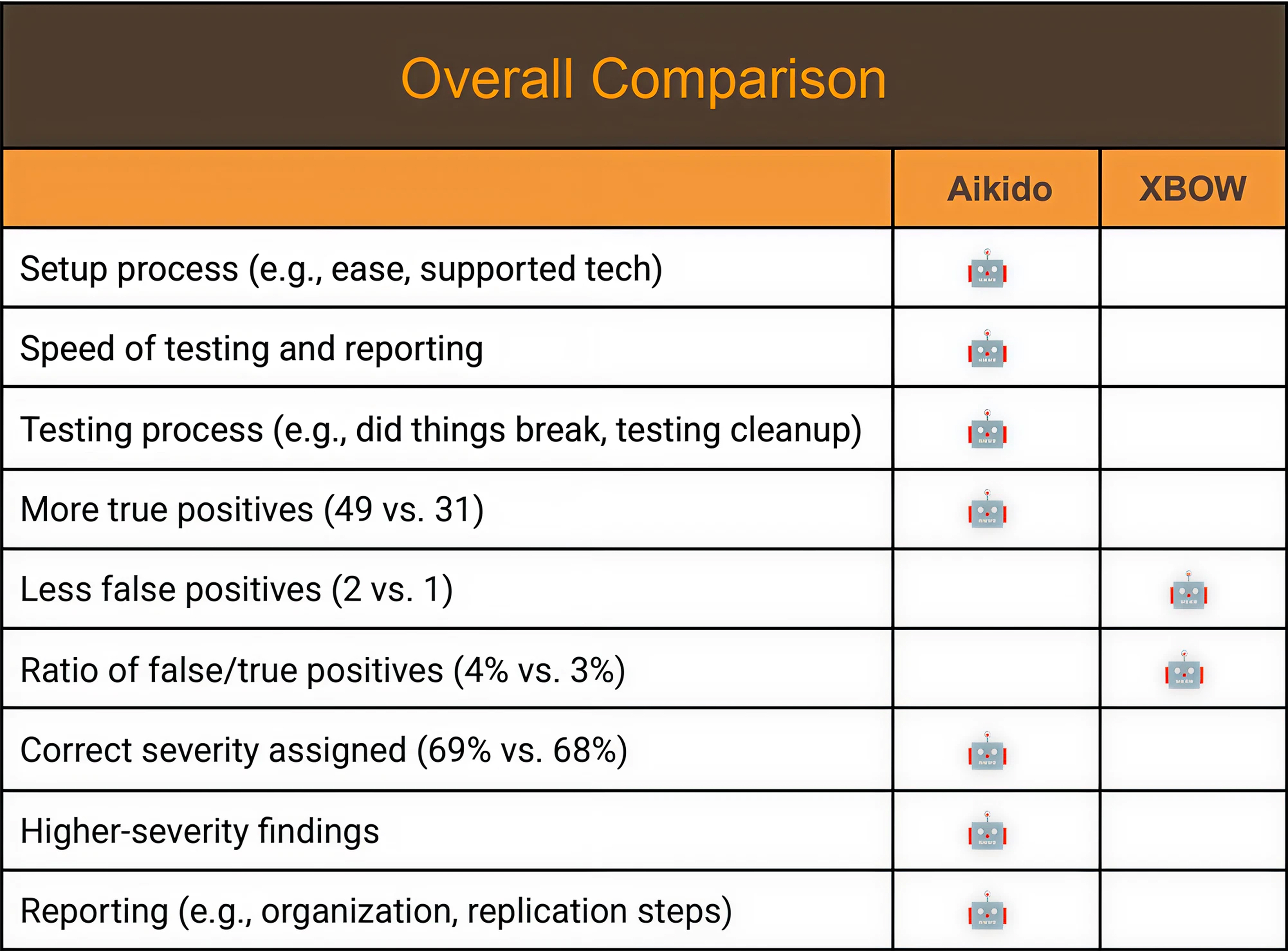
"Aikido showed an advantage in the setup process, overall testing and reporting speed, and in how its testing approach affected the target application and surrounding environment. It also identified a higher number of true positives and delivered somewhat stronger reporting quality."
We commissioned this benchmark because we thought it would show Aikido performing well. It did. Independent research is only worth commissioning if you publish what you get.
The full report, with methodology, all findings, and the raw data spreadsheet, is available on our reports page.
Read the full Doyensec report →
Want to see what Aikido finds in your own application? Book a demo →


